

Table of contents
“Data is the new oil” is a phrase attributed to British mathematician Clive Humby in 2006. While data has undoubtedly become one of, if not the most, important currencies of the modern economy, there are enormous differences between good-quality data and bad-quality data.
Bad-quality data has negative value. It can mislead. It can overwhelm and lead to inefficiencies. Some call it the Data Swamp. This is a big part of the motivation behind FDA’s emphasis on Data Integrity.
Often, bad-quality data is the result of lack of structure. Unstructured data needs to be refined into structured data for it to provide real value.
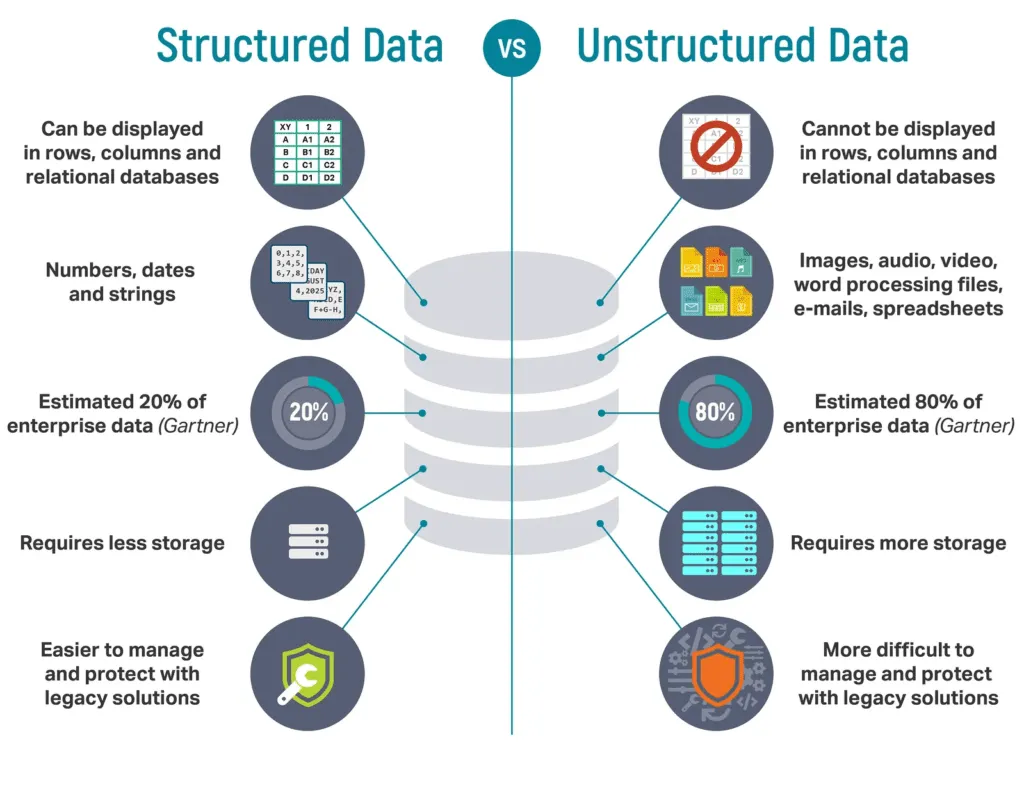
Figure 1 | Structured data vs. unstructured data
Unstructured data, like thousands of PDF documents of written reports in the case of FDA 483s for example, poses a unique challenge for analysis. However, there’s a game-changing solution being rapidly developed now – Intelligent Document Processing (IDP). In this post, we’ll explore how IDP can transform your data by structuring unstructured content, unlocking its full potential for sophisticated analysis.
The Challenge of Unstructured Data
Unstructured data is the raw, untamed beast of the data world. Think of the millions of unstructured documents, emails, and images that organizations accumulate daily. This unstructured data is challenging to manage and analyze because it lacks a defined format, making it difficult to extract meaningful insights. Without proper structuring, the goldmine of information within unstructured data remains largely untapped. Enter IDP.
The Benefits of Structuring Unstructured Data with IDP
Intelligent Document Processing is a game-changer. It’s a technology that combines machine learning, artificial intelligence, and natural language processing to make sense of unstructured data. By applying IDP, you can turn unstructured data into structured, actionable insights. Imagine the ability to automatically extract key data points from invoices, contracts, or customer emails. With IDP, you can achieve this and more.

Figure 2 | Data Layers pulled from a form 483
In the case of Redica Systems, we’ve built our own IDP system to make sense of the thousands of Quality and Regulatory documents we ingest from agencies like FDA, MHRA, EMA, and Health Canada. It’s called Redica DocIQ. Instead of the old way of printing out a PDF of a 483 or of a new guidance document and combing through it manually with a highlighter, Redica Systems can scan the document and automatically tag the relevant observations.
Not only does that make interpreting that individual document easier, but more importantly, it allows Redica Systems customers to see patterns and trends across thousands of similar documents. That leads to real insights with impactful business benefits.
In this way, we’ve turned what could have been a data swamp into something very valuable.
Techniques for Structuring Unstructured Data with IDP
IDP uses a variety of techniques, such as Natural Language Processing (NLP) for text data and Optical Character Recognition (OCR) for images, to structure unstructured content. For example, using NLP, IDP can extract important information from text documents, like sentiment analysis, named entity recognition, and keyphrase extraction. This is invaluable for tasks like extracting critical terms, like GCP vs. GMP, from agency enforcement documents.
Successful IDP Case Studies
In the healthcare industry, structuring unstructured data is crucial for improving patient care and outcomes. Healthcare providers often deal with vast amounts of unstructured data in the form of patient records, clinical notes, and medical imaging.
Healthcare organizations like Mayo Clinic and Cleveland Clinic have adopted IDP solutions to process and structure this wealth of information. These systems utilize Natural Language Processing (NLP) to extract vital patient information from clinical notes, prescriptions, and medical histories.
The structured data is then integrated into electronic health records (EHRs) and analyzed to identify patterns, trends, and potential health risks. This helps physicians make more informed decisions, reduces errors, and enhances patient care. Additionally, structured data from medical images aids in diagnosis and treatment planning, further improving healthcare outcomes.
Future Trends in IDP and Data Structuring
The future of IDP holds even more promise. As artificial intelligence and machine learning continue to advance, IDP capabilities will expand. Enhanced IDP solutions will provide increasingly accurate data structuring and extraction, opening up new possibilities for advanced analysis and insights. At Redica Systems, we are continuing to rapidly innovate our IDP capabilities alongside our other uses of AI and ML to deliver our customers even more value.
Conclusion
In a world overflowing with unstructured data and the resulting data swamps, Intelligent Document Processing is an important part of a solution. It transforms chaos into clarity, unlocking the true potential of your data for sophisticated analysis. For Redica Systems’ audience of quality and regulatory professionals in life sciences, Redica DocIQ can revolutionize the way you work.
Ready to see how Redica Systems can work for you and your company? Request a demo today.
