Table of contents
At the PDA Annual Meeting in late March 2024 in Long Beach, California, Redica Systems CEO Michael de la Torre presented a vision for how artificial Intelligence (AI) can reveal enforcement trends in data integrity inspection findings and the work his company has done to date to realize that vision.
He began by referencing a presentation he gave in September 2023 at the PDA/FDA Joint Regulatory Conference in Washington, DC, where he referenced what he called “Denyse’s Dream” as he understood it from Eli Lilly Associate Vice President for External Engagement and Advocacy, Denyse Baker.
When asked what she wanted from a quality/compliance standpoint from AI, according to de la Torre, “she put it very succinctly. The first thing is, ‘I want the system to be able to tell me there is something interesting that I need to care about – something relevant that I need to care about that happened in the outside world.’ The second thing is, ‘how big is this issue?’ So, you need to look at all the other data that potentially connects to that event from the outside world.”
Her third wish from an AI system was for the system to let her know if her company has the same issue. “So, you need to look at deviations, you need to look at audits, you need to look at batch records, et cetera. So basically, a smart system that can help you identify when something happened, tell you how widespread it is, and then potentially look at your internal systems to give you a handle as to what is going on,” the Redica Systems CEO said.
Finally, Baker wants alerts on the topic as it evolves to be able to plug into her workflows. “This was Denyse’s dream and we have a long way to go to get there” de la Torre commented, noting that his company is well on its way, perhaps 60% completed.

Figure 1 | Source: Redica Systems
“It is not this,” he said, referring to the above cartoon. “There is a quick and easy way to get to fun, interesting demos, and that is to use off the shelf LLMs and just sort of throw it at the unstructured data. You get some really interesting answers. It can help you from time to time. But these things hallucinate a lot. They make up CFRs. They do a bunch of other things that are weird and so we did not take this approach. Our approach is that the Chatbot or the copilot comes last. You can write that. The copilot comes last, not first. That is our approach.”
It looks a little bit more like this – the approach on the right:

Figure 2 | Source: Redica Systems
“The answers take a little bit longer to get to, but when you do get to them, they’re accurate, they’re specific, they’re repeatable, they’re explainable, they’re auditable, and connected back into your data model. The system is maintainable and then extensible to other data sources. So that is the approach that we are taking.”
The Redica Systems CEO proceeded in the next section of his presentation to walk through a high-level “AI practitioner’s guide” explaining how his company approached building its AI system. He ended with specific work that has been done and shared examples around data integrity inspection findings.
Building the AI Models
“What I am going to show you today, nobody has ever seen before because we just rolled all the models out this month. So, it is hot off the presses and it is going to be pretty exciting,” de la Torre commented.
Following is the Redica System CEO’s slide presentation and the complete narrative he provided with it.
This is our approach:
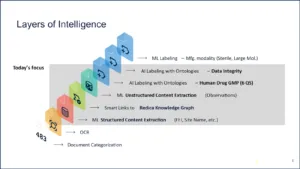
Figure 3 | Source: Redica Systems
We add layers of intelligence to unstructured data. This is kind of what anybody would have to do. This is our approach, but in order to solve these problems, at the bottom layer you have to classify the document, you have to extract text, you have to extract structured fields, you have to link those structured fields to a knowledge graph. What does all this mean? We are going to go into it.
Then you must do unstructured content and extraction. Then you need to put it through a series of different labeling methodologies to basically embed intelligence on the top of it.
Every expert, when they grab a warning letter, when they grab a regulation, this is what they are doing with their highlighter, right? They are looking through the structured information, they are reading it, they are getting their highlighter, they are annotating it, they are labeling it, and then they are passing it on.
To get a machine to do it, you have to create eight to 10, to 15, to 20 discrete steps to basically replace that work. Each layer has to be discrete and independent and measured and maintainable. That is how you start augmenting and replacing or enriching human work and really, really getting this automation. I am going to walk through that.
Structured content extraction: Everybody has seen this. You build models to deal with different documents. Text to tables.
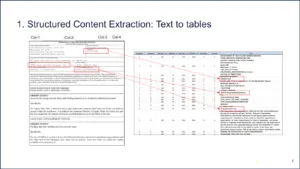
Figure 4 | Source: Redica Systems
Second is you have to link it into a broader knowledge graph. So, you have to extract entities and link entities. In our case, we do inspection, enforcement, and regulatory documents, and inspectors. We have products, sites, people, and then sub events that have to get linked to that. And so that is how you are able to get the facets to say, “I want to see all 483s that led to a warning letter.”
To do that, you have to link the 483 to the inspection and the inspection to the warning letter and it has to be in the same data model that you can then query. For example, “Show me recalls from sterile generic sites.” You have to link recalls to the sites and then enrich those sites with different facets to be able to run those kinds of queries.
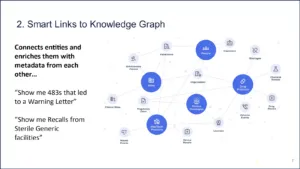
Figure 5 | Source: Redica Systems
The third step is unstructured content extraction. You take the observation, you break it into sentences, then you apply ontologies. What is an ontology? An ontology is a representation of meaning. In this case, this is a human drugs GMP. Two hundred and thirty categories, six quality systems, subsystems, sub-subsystems, four layers of intelligence.
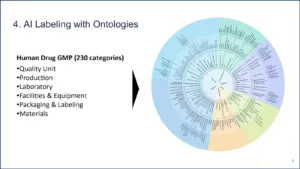
Figure 6 | Source: Redica Systems
How many people do audits? How many categories are in your audit framework? A hundred, a hundred seventy, two hundred, two hundred thirty? More than 10, more than six. How useful is it to label something simply “lab?” Not very useful at all, right? You got to get down to the second, third, fourth level because that is where the meaning really is. We have created an ontology for GMP. That is this pretty chart.
Next let’s look at data integrity. We created a framework with 15 different categories. Basically, it has some ALCOA+, some records controls, data manipulation, data destruction, testing into compliance. That is how we label data integrity.
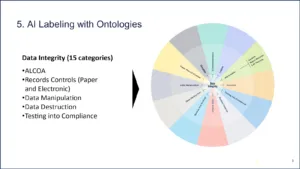
Figure 7 | Source: Redica Systems
Then you have to apply those models to the parsed text because you need that actual location on the document where this label came from.
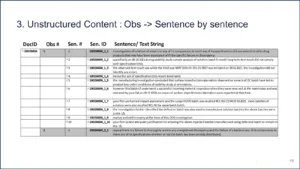
Figure 8 | Source: Redica Systems

Figure 9 | Source: Redica Systems
In the case of this one sentence outlined in red on the slide, the first model said, “This is human drug, GMP, for sure. It is quality unit, reviews, and approvals, deviations, investigations.” So, it is an investigation issue dealing with reviews and approvals, and we scored that possibly major. The second model actually got a positive result, but it said this is definitely not data integrity.
Once again, you have patterns and anti-patterns to labeling. It either definitely has the label, it is silent and did not find any label, or it is determined to not be data integrity.
We run into issues like that with modality – for example, sterile or not sterile. Is this a sterile facility? Maybe we can’t tell, but we definitely know it is not sterile. We have patterns and antipatterns in these labels, so I wanted to show you an antipattern.
How did we do it? Basically, we took thousands of sentences, we labeled the thousands of sentences, we extracted the semantic meaning and that becomes our vector database. This is an example of one of the sentences in our gold vector database. This is an example of an issue with data backup. We lifted this from a 483.
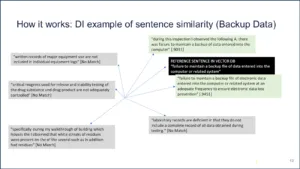
Figure 10 | Source: Redica Systems
Our Senior GMP Quality Expert, Jerry Chapman, said this is definitely a backup issue with data integrity. We have dozens of examples of sentences for data backup. When you look it up, these sentences right here with the gray background do not match the sentence we are looking at – they are not data backup or data integrity. The sentence with the light green background do. One is a 0.9 match. “During this inspection, I observed the following.” So, a bunch of extraneous information. “There was a failure to maintain a backup of data entered into the computer.”
You think we got that one right? You think that is data integrity backup? Yes. The model says 0.9 there. You need to think of this thing like the Richter scale. If it is 1.0, it is a complete match, and then a 0.7 is almost no match at all. So don’t think of them as percentages – it’s more of like a log scale.
This one sentence is a 0.94. It is almost the exact match of the language that we had in the golden dataset. So basically, that is what it is doing. It is just like a human. You have a bunch of things in your mind and you know things. You see something and you are like, “Yeah, that’s backup,” because you have this semantic meaning in your mind. And what is your confidence interval that this is backup? Well, I am pretty confident, say 94%. A human would say probably 100% to that, but the models aren’t perfect.
As I said, when you run these models, you get a whole distribution of text. When ChatGPT is doing it or with any LLM you guys use, all of this is behind the scenes. So, we are basically just exposing it to you and you can pick a confidence interval. For anything over a 0.87, it tends to be right. Anything under a 0.87 tends to be wrong. That number is arbitrary. We picked it.
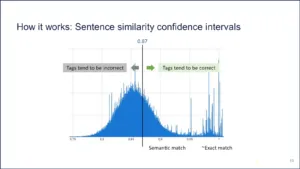
Figure 11 | Source: Redica Systems
If anybody says that their AI models are not biased, they are lying to you. Every single model is biased. It is biased by its creator. In the case of our model, it is heavily biased by me, it is heavily biased by Jerry Chapman, heavily biased by a number of our other analysts we have in the company. So absolutely, it is biased, but hopefully your bias agrees with our bias.
AI Model Evaluation of Inspection Data
Now we are going to review some results. We are halfway through, and now we are going to show some trends that you have never seen before.

Figure 12 | Source: Redica Systems
What data did we review?
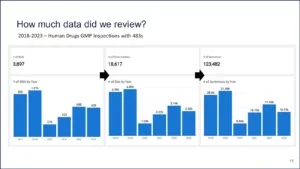
Figure 13 | Source: Redica Systems
Data from 2018 to 2023. We went pre-COVID, during COVID, and post-COVID. We selected 483s that were human drugs CGMP. We selected the labeling to kind of get those different piles. The data set is from 3,897 483s with over 18,000 observations and 123,000 tagged sentences. How long do you think it would have taken humans to go through and tag 123,000 sentences? Do you think that that is possible? It is not possible. Actually, it takes a team of dozens of people in the Philippines and then they get it wrong. So, you don’t want to do that either.
Now a pop quiz time – interactive time. Does anybody know the answer to this question? Is data integrity being cited more or less since 2018? Who thinks it is way up? All right, who thinks it is slightly up? Who thinks it is no change? Who thinks it is slightly down? Who thinks it is way down?

Figure 14 | Source: Redica Systems
It is way down. We counted 483s, we counted observations and we counted sentences. Here are the three results.
I don’t have an explanation. We did not go through it. That is not the purpose of this. “Well, Michael, what’s going on?” I don’t really know. But I do know that it is just math. It is just the labels, 0.87, from our model. We are going to continue to improve the model. I don’t think it is majorly wrong, but DI citations are not up, I will tell you that. It might not be down this much, but there is something intriguing going on with it. We are going to go into some further details.
On an observation basis though, it is only slightly down. So basically, what this is telling me – and on a sentence basis, it is only slightly down – that data integrity is tagged on fewer 483s, but when they tag it, it shows up more.
On average, there are more observations with it than less. This is a primary tag. A primary is the first sentence of the observation, and a secondary would be a second sentence. So, I just did the primaries. We can also look at secondary tags, et cetera. So don’t go running off and doing too much with this information because there are caveats to everything.
Even though I had just told you we didn’t use ALCOA+ directly, we came up with a different model, does anybody have a guess as to what is the most cited data integrity category?
Complete data.

Figure 15 | Source: Redica Systems
Everything in the ontology got tagged at least once. But as you see here from primary issues in the first sentence of the observation, complete data was the number one thing being cited. System controls was second. Now this changes a lot when you look at secondaries and some other things. We are going to look at some other cool things. But that was the answer. Attributable batch records category was the third most tagged.
How does this change when you look at just 483s that were 483s and never turned into a warning letter, an OAI, or had an import alert or any red thing, bad thing happened to it, versus ones where it had a warning letter attached to it?
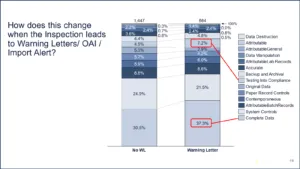
Figure 16 | Source: Redica Systems
There are only two things that are much different. Complete data gets cited more when there is a red inspection and then testing into compliance or the opportunity to test into compliance. We were a little short with our tag here. It would be the opportunity to test into compliance or actually testing into compliance. It’s kind of both. Basically this tag means that you don’t have controls or explanations of why you are aborting runs and things like that. So that’s what we call testing into compliance. That ticks up in warning letters, but really there are no changes other than that. That was kind of an interesting finding.
When DI is cited as the primary observation, which Human Drugs GMP category is being mentioned with it? Do you guys have any idea how many times I’ve been asked this question? When data integrity is cited, where is it happening? Of these six quality systems, what else gets cited? I will give you a hint. There are three, and they are kind of the same. Does anybody want to guess what the three quality systems are? And then there are three that basically almost never get tagged with data integrity.
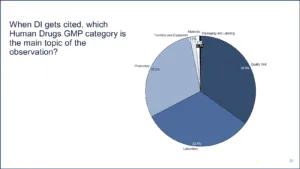
Figure 17 | Source: Redica Systems
It is a deficiency of the quality unit if you don’t have data integrity because of the responsibilities of the quality unit. You don’t have good procedures around it, you don’t have good systems. So just a generic data integrity finding… They are not really talking about any other quality system. They are saying your quality unit is bad around data integrity, right? That is the big first one.
Then the second one is data integrity in the lab, and the third one is data integrity in production and the other three don’t really get cited much with that.
That was a cool finding that kind of fits intuition. Some other findings do not fit intuition. When complete data is being cited, it maps to three quality systems. The three we kind of talked about, but what’s the top one? Anybody have a guess where complete data is a problem?
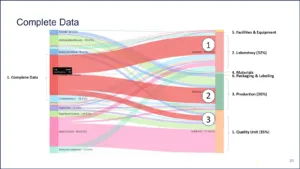
Figure 18 | Source: Redica Systems
This is a Sankey chart. This shows data streams flowing from one stream into another. On the left you have the data integrity findings. So that pie chart we just did with complete data is number one. That’s on the left. The data integrity category “complete data” maps to three quality systems on the left – laboratory first, production second, and quality unit third. This is blending the two models.
And then when we look at system controls.
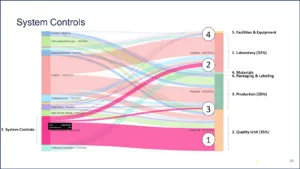
Figure 19 | Source: Redica Systems
System controls almost always map to the quality unit and then second to the lab, third to production, and fourth to facilities and equipment. So pretty cool stuff, huh? All right. Anybody ever seen anything like this? Anybody do it for themselves with a highlighter? No? The next question is, how do data integrity categories change from year to year? Are they totally different from year to year or is it pretty much the same stuff? What do you guys think? Does it change a lot or changes a little or does it change at all?
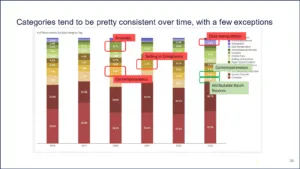
Figure 20 | Source: Redica Systems
It changes a little. It is mostly stable. This is a different chart – now we have years going across the bottom. The categories don’t really change over time. There have been a couple of times where accurate data kind of popped up as a percentage. Contemporaneous popped up as a percentage. Testing into compliance popped up. But once again, that was during COVID and there were more warning letters per inspection so that is not surprising.
And then data manipulation just popped up last year as a higher percentage, but then contemporaneous and attributable batch records kind of went down. Once again, we didn’t really dig into it to look, but it did cause us to look at one other thing, which is really cool.
You remember we talked about that vector database where we have a lot of sentence examples, which form the knowledge corpus that the models then use for tagging?

Figure 21 | Source: Redica Systems
On the left-hand side, it is a bunch of truncated sentences. These are some of the sentences for system controls. The percentages are the system control matches for that year – what percentage of those matches use that evidence from those golden sentences. And you see some really interesting things.
Look at the 5.8% in the middle of the page. “Failure to assure adequate control of your data integrity” is a new way that the FDA is talking about it. It just popped up in 2023 – it wasn’t used hardly at all before that, and now it has popped up and it is 500 times more likely to be used, that sentence, as a match than it was previously.
And then there is another new sentence – “Failure to maintain complete data derived from all testing.” So, they are being a little shorter, a little more concise, and a little more direct with their data integrity language is what this would tell me.
To finish up, Denyse’s dream is fully achievable. As I said, we are probably on step six of 10 of integrating all of these things, what I showed you with to get accurate, specific, repeatable, and ultimately explainable information.